The Agent‑Native Runtime
Golem runs ordinary, stateful code as durable, distributed agents. It provides production behaviors at scale—without rebuilding infrastructure for distributed systems.
Build & Deploy
1. Define
Write your agent using normal TypeScript code
2. Grant
Declare tools, agents, and APIs it may call
3. Deploy
Publish your new agent type to the runtime
4. Trigger
Create and talk to agents using secure APIs
5. Observe
Monitor, debug, repair, and upgrade
Production Guarantees
Transparent Failure Recovery
Seamlessly recover from node crashes and infrastructure failures without lost progress or manual intervention.
Exactly‑once external effects
retries never duplicate charges, webhooks, or other side‑effects
Durable internal delivery
agent‑to‑agent messages are persisted and delivered once
Suspend and resume
pause for human approval, scheduled wake, or idle standby at zero compute; resume instantly
Automatic recovery and back‑off
transient failures retry to policy limits
Isolation and permissions
one agent cannot crash, read, or act as another; capabilities are scoped
Observability with rewind
inspect full history and replay safely without duplicating effects
Zero‑downtime upgrades
run versions side‑by‑side or migrate live agents forward
How It Works
1. Deploy an Agent Type
Deploy your agent logic as a reusable, secure unit on Golem’s WebAssembly-based runtime
.png)
2. Create Agent Instances
Run any number of isolated agent instances, each with independent, oplog-backed durable state

3. Automatic Operation Logging
Every action—state changes, I/O, API calls—is automatically logged for recovery and insights
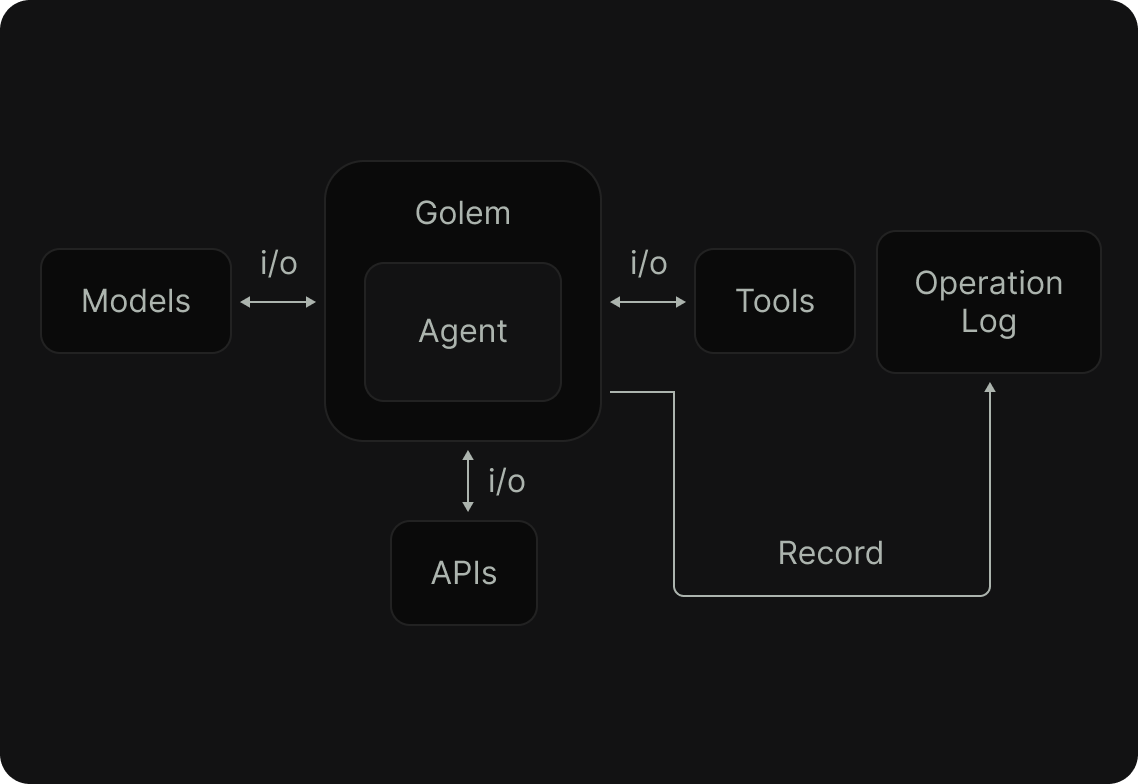
4. Seamless Failure Recovery
After interruptions, Golem reassigns the agent, replaying the oplog to restore the exact state
.png)
5. Transparent Resumption
Your agent resumes precisely from where it left off—no lost state, no duplicate work, no extra code


.svg)
.svg)
.svg)
.svg)
.svg)
Integration
Golem supports writing agents in the TypeScript programming language, with more languages on the way, and full two-way interop with your existing APIs, tools, and agents
Start building or shifting use cases that benefit the most from Golem’s reliability, and retire your existing complex infrastructure over time
Start building or shifting use cases that benefit the most from Golem’s reliability, and retire your existing complex infrastructure over time
Your stack → Golem
Trigger agents via platform endpoints; send commands or messages
Golem → Your stack
Agents call your services over HTTP under exactly‑once mediation; connect tools via MCP
Ready When You Are

