Durable Execution Engines are making their revolutionary entrance into the software engineering space. In this blog, we will explore how they are penetrating the data engineering field with the help of Golem, the most intuitive Durable Execution Engine I have encountered, and an implementation of TimeLine Analytics based on Golem.
I aim to bridge Durable Execution Engines with Data Engineering using Golem Timeline and demonstrate how this can provide a strong foundation for solving extremely challenging problems in data engineering.
Prelude
For those who work in the data engineering space (or even in the software engineering space building scalable backends), almost all frameworks and system designs expose a few terms (or their synonyms) that are quite common.
- Job: Responsible for solving a problem (e.g., finding the total number of users logging in from a particular country).
- Executor/Task: A unit of a job that handles a section or all of the (possibly large) data. We will refer to them as workers soon.
- Streaming Job: Deals with a stream of events (e.g., credit card events in the financial domain, temporary aggregations to make the final aggregation less computationally intensive, online (near) real-time reporting, etc.).
- Batch Job: Instead of computing data as it comes, the data is stored in a cluster, and the job runs once to process all the data.
- State: Internal state needed as part of a streaming/batch job.
- Cache: To reduce reads from the underlying data store or disk every time the executor needs to access data in-memory during computation.
Proper data analysis often requires a well-engineered data pipeline, demanding extensive system and programming knowledge, along with an in-depth understanding of each framework (e.g., Spark, Apache Flink). While these frameworks help solve various problems, their limitations and complexities stem from a few fundamental issues. Here is a typical problem a framework has to solve:
What if an executor performing a section of the computation fails in between?
Some frameworks address this issue by rebalancing consumers using a global orchestrator, which can be a single point of failure. Here, the consumer is a simple process that listens to a section (partition) of events.
If consumers are stateful, using an in-memory cache to enhance performance or as part of core logic needing intermediate results before processing further events, the rebalancer must migrate this cached data to the new executor to reduce downtime. However, this cached data can’t be in-memory since the rebalancer can’t access the internal data of a terminated executor. In this scenario, the consumer logic must rebuild the state from scratch (as those familiar with Kafka and RocksDB will understand) from a more global source, likely a distributed cache.
Today’s frameworks often use a global cache, which is a mix of all data sets organized in certain ways (indexing, partitioning, etc.). This can quickly become a big data set, leading to significant challenges in maintenance and debugging during failures. This issue exists in every backend architecture striving for scalability, with one solution being the use of sharded databases, though the details aren’t relevant here.
The Fundamental Problem
In short, due to failure scenarios, we cannot assign a particular executor to a deterministic set of data, as executors (or consumers of streamed events) may keep failing, requiring other executors/consumers to handle their data sections.
This fundamental problem of an executor not being deterministic (with changing data responsibilities) leads to various issues that users and framework developers must solve using complicated system designs.
A Suboptimal Foundation — leads to problems that shouldn’t have existed
- We don’t have access to sub-computational result in a larger computation
- Users need to specifically handle the reuse of computation results across the jobs. Example: We have no way to say “executor X may have the total current number of buffer events faced by user X ”. Had it been possible, we would have reused that data in the next job which only calculates the total buffer events for each user.
- In-memory caching becomes secondary, necessitating distributed cache, along with resource and lock management. Backend engineers face the issue of not being able to ensure a load balancer always hits a specific node to read the cache, as that node could go down. Even stateful nodes aren’t helpful because they only provide a deterministic identifier, not durable cached data.
- Bespoke engineering around existing frameworks in maintaining state, cache and boosting performance of the entire system requires specific framework knowledge.
If you think about it, this is all due to the opaqueness of the jobs performed by these data engineering frameworks. All you get is a plethora of graphs showing the progress of random tasks running in various nodes, whose responsibilities with respect to an entire logic of computation is vague!
I’ve submitted a job to Spark, but I’m unsure about its internal workings. I’d like to understand what’s happening and where, so I can potentially reuse some of the intermediate datasets this streaming job produces in my next streaming job without needing to engineer too extensively with the framework or the data.
These are not the only problems this blog is trying to address, so please read through the entire solution, which further resolves issues related to stream joins, existing watermark solutions, potential memory pressure, out-of-memory errors, watermark-based evictions, TTL, and more!
Developers have moved on from discussing problems around caching, state management, big-data and so on, but they haven’t escaped from it yet.
The Hard Problems And TimeLine Analytics
From now on, let’s focus on some extremely hard problem statements in data-engineering space. Many of these are hinted within the paper.
Video Streaming
How long did the user spend re-buffering the video from CDN1, excluding ones within 5 seconds after a seek?
Financial Domain:
Did the user swipe credit card twice within a span of 10 minutes from different suburbs?
Lineage of bank card history correlated with transaction anomalies
Manufacture
Duration of risky state before machine failed
Marketing Analysis
Did an iPhone user stop advancing in a game when the ad took ≥ 5 seconds?
Why are these problems hard?
This is almost a re-iteration of what’s discussed above.
- Complicated State management in a streaming context
- Extremely complicated SQL queries, and even more difficult when they are streaming SQL queries
- Vague boundaries of stream vs batch
- Suboptimal handling of delayed events — watermarking, checkpointing, state eviction, possible OOO.
- Over reliance on persistence during computation
- In-memory caching being a second thought in front of distributed caching
- Zero application level compute reuse
Solutions in various ways:
- Spark Streaming, Delta Lake
- Amazon timestream, Apache Flink and so on!
- Other Bespoke solutions
So the first step here is to form the right abstraction to solve really hard data engineering problems before we integrate it with a killer backend such as Golem.
The timeline analytics paper discusses solving one of these problems using PySpark, and it looks something like below.
We are not going to explain this query. With the new ideas from the paper, we never need to write this.

What do we need exactly?
- We need a DSL backed by the right primitive, allowing composition, observability and optimisations
- We need an executor that’s deterministic, and integrates well with the DSL
- An executor that’s transparent to the developer, from a domain perspective
- Be able to come back and peek at these tasks/executors anytime
Inspiration to Golem Timeline
I have personally tackled the initial problem at a major streaming company: computing CIRR (Connection Induced Rebuffering Ratio). The company explored all existing solutions before settling on a bespoke approach involving Golang and Scala, centered around a custom-built data storage layer. While this approach resolved many issues, it still suffers from suboptimal design due to distributed cache challenges, lengthy SQL queries, blurred boundaries between streaming and batch areas causing occasional slowdowns that are borderline unacceptable. Moreover, managing delayed events remains a significant challenge.
At the end of the day, our goal was simply to determine how much time each user spends re-buffering video from CDN1, excluding instances within 5 seconds after a seek.
After a couple of months, I was lucky enough to to work for Golem, with an astonishingly efficient and incredible team who are also authors of one of the most successful initiative in Scala Space — ZIO!
At the same time, I also came across this insightful paper in the data analytics field. It introduces a promising abstraction called TIMELINE to address these challenges.
Now, let’s delve into what TimeLine is and how it solves these issues, particularly with CIRR.
What is a Timeline ?
I recommend reading the paper if possible. However, I can simplify the terms here. This section doesn't explain Golem-Timeline but only the idea of Timeline. Refer to the diagram below.
We plot 4 timelines based on incoming events:
- “Has the user ever started playing”: The application found that this is at T1 when reading the events. It’s a boolean plot that turns true after T1.
- “Has the user ever performed a seek”: We observe this at T2. Similarly, it’s a boolean plot that turns true after T2.
- There’s a third timeline in the diagram identical to the second one, but intentionally set to false after a configurable 5 seconds. This adjustment reflects that users don’t seek indefinitely.

4. The fourth timeline is quite intriguing. It’s a derived timeline based on another timeline that plots all states (such as seek, buffer, play, pause, etc.) as string values over time. We then apply an “EqualTo” operation on this timeline with the string value “Buffer”, which produces a plot indicating the time period during which the state was “Buffer”.
The technical details of how we precisely plotted this are not relevant at this moment, so please bear with me until we discuss that.
In the above figure, we really don’t need the second timeline. Therefore, we removed it from the diagram.
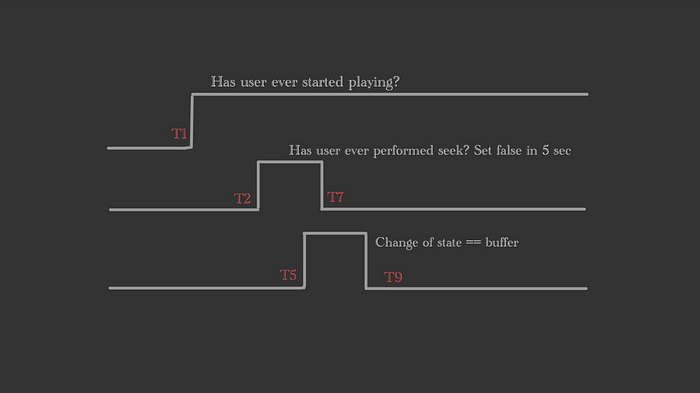
For simplicity purpose our TimeLine is just a collection of time -> event-value pair. If that’s the case, we can do a Logical And between timelines. At this point, we are not even talking about any streaming, but simple code that does a logical And . In the above diagram if we do a logical And of all these three timelines, we get the following:
“The total time period of buffering while the user was seeking”
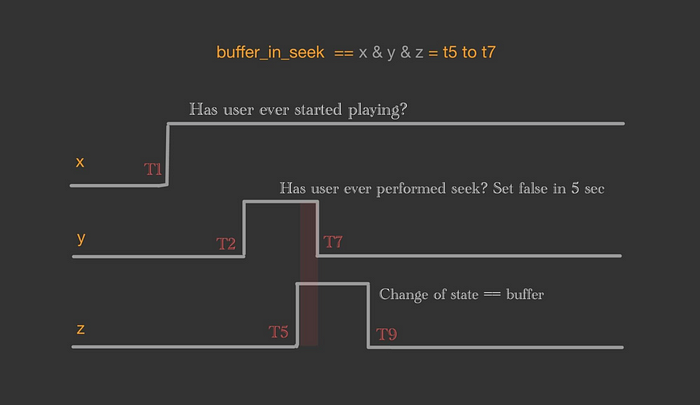
So how do we compute the total buffer time that’s not part of the seek event?

We simply flip the second timeline (using not ) and then do a logical and of x, y, and z . Now we get the buffer time that’s not because of the seek event!
TimeLine Paper exposes the following DSL to represent various types of operations.

Here is how you can map the above explanations to the above diagrams.
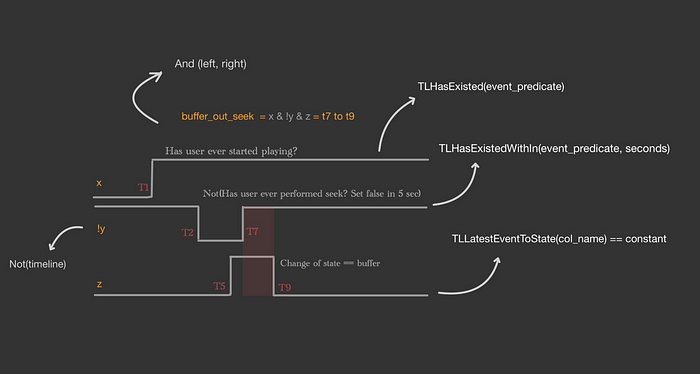
How to use Golem Timeline?
As you know we are building this idea using golem-timeline where users will write domain logic as follows:
// Timeline DSL
let t1 = TLHasExisted(col("playerStateChange") == 'play')
let t2 = TLHasExistedWithin(col("userAction") == 'seek', 5);
let t3 = TLEventToState(col('playerStateChange')) == 'buffer';
let t4 = TLEventToState(col('cdnChange')) == 'CDN1';
let result = And(And(And(t1, !t2), t3), t4);
result.at(2pm)
You can compare this with the screenshot above that shows pyspark logic.
Golem-Timeline is in development which pipes in powerful features on top of this wonderful abstraction because it is based on Golem — which is a durable execution engine that exposes stateful workers (executors) that live forever.
What is Golem?
Taken from its website: Golem is an evolution of serverless computing that allows workers to be long-lived and stateful. Through a new paradigm called durable computing, workers deployed onto Golem can survive hardware failures, upgrades, and updates, offering a reliable foundation for building distributed, stateful applications.
This description straight away address many of the burning concerns discussed above.
What does this mean for Timeline?
Now that you have seen an example of a timeline operation, such ashas the user ever started playing, or the duration in which user was seeking . Internally timeline will be a group of workers listening to events or other workers performing the logic based on the DSL node and these workers are durable. The state of these workers are simple in-memory map. This implies deploying golem-timeline in your company doesn’t involve a plethora of infrastructure requirements.
But the main point here is, this worker or group of workers live there forever and you can poke them to get the current status of, say, seek events! The responsibility of each of these workers doesn’t change. Also developing timeline using Golem didn’t require learning any other framework or language. Just plain Rust application to a significant extent!
Golem Timeline in fact can tell you which part of the computation is taken care which part of the executor (the worker), again, forever!
Internals of Golem Timeline
Users of Golem Timeline don’t need to worry about the internals, but it’s always beneficial to understand what’s happening! If you feel it’s too much information for now, you can skip this section.
- Every Timeline DSL node is a Golem worker — That’s long living, stateful and durable!
- A worker in a Golem is an instance of a web assembly component.
- In golem-timeline, its a simple Rust workspace with a
driver,timeline,core (orchestrator),event-processorandtimeline-processor. We will explain this! - But these modules are simple Rust applications which can be compiled to a WASM components, and deploy it against
Golemand that’s it. - Obviously these modules are dependent on each other and how to create dependency between web-assembly components is explained here, but it isn’t necessary to read this at this point. Just save it into your reading list
One of the modules in Golem Timeline is the timeline, which serves as a library reused by other modules. One of its critical components is the representation of the timeline DSL itself.
pub enum TimeLineOp {
EqualTo (WorkerDetail, Boxr<TimeLineOp>, GolemEventValue),
...
Or(WorkerDetail, Box<TimeLineOp>, Box<TimeLineOp>),
Not(WorkerDetail, Box<TimeLineOp>),
TlHasExisted(WorkerDetail, GolemEventPredicate<GolemEventValue>),
TlLatestEventToState(WorkerDetail, EventColumnName),
...
TlDurationWhere(WorkerDetail, Box<TimeLineOp>)
}
Here you can see every node is annotated with the WorkerDetail (the worker in which this node is going to be running). GolemEventValue is nothing but the actual event, which should have an EventId and a Value which is enum of String , Float etc. Again details to this level aren’t too relevant here to understand the concept of timeline.
Leaf and Derived Nodes
We then classified the Timeline nodes as either Leaf or Derived. Each node in the timeline DSL has specific semantics. For example, TLHasExisted consumes events directly to plot a timeline that answers “has the user ever started playing, and if so, when?”. On the other hand, a node like TlDurationWhere consumes the output from another worker, where the output is typically a timeline of states. Refer to this part of the timeline paper for more details.

Here the first two nodes can be seen as leaf node and the last one can be seen as derived nodes.

Event Processor (event-processor module)
- All leaf nodes are implemented into a web-assembly component, and we call it event-processor!
- They are called event processor because their input is an event timeline
- The output is timeline of states
- These three leaf node functions within 1 component module can run as one worker, or multiple workers, that’s going to be configurable
Timeline Processor (timeline-processor module)
- We write another component called timeline-processor that implements rest of the derived nodes
- Every functions in this component takes another timeline as input
- They take the input from either another instance of timeline processor or event-processor
- These nodes may work as a single worker or multiple workers
Any state backing these functions are simple Rust datastructures. There is no need to learn nuances of another framework. We were writing simple Rust program and build a WASM component to work with Golem
Core Module — The orchestrator
We have a third component called core (the core engine) that parses the DSL that’s coming from the driver
Core orchestrator assigns the work to various other workers and builds a real execution plan. This part may change in future, but as of now you will get a concrete full plan. This may not be true as time goes, but those details are not relevant to the conceptual explanation of golem-timeline.
It is another WASM component, that’s deployed with Golem. So you don’t need to worry whether this orchestrator fails or not :) =
Driver Module
This is simply another web assembly component, that’s the starting point of the entire workflow.
Final Workflow
- Write the TimeLine DSL in Driver (as of now)
- Driver sends it to the core engine
- Core traverses through the timeline definition and instantiates and informs the workers of other workers
- Core returns to the driver of the execution plan that includes worker information
{
"event_processors": [
{
"LeafTimeLine": {
"TLHasExistedWithin": {
"time_line_worker": {
"component_id": "aa23e1a4-3384-43c1-8c33-7c74cb2ab2e5",
"worker_id": "cirr-le2s-playerStateChange"
}
} }
} ],
"result_worker": {
"DerivedTimeLine": {
"Not": {
"result_worker": {
"component_id": "7fd082fa-0063-473e-8061-6fd5cca7a3ac",
"worker_id": "cirr-tl-not-8b54ef0b-8814-4b3d-bb6f-3a91147a7a36"
}
} }
} }
This is the current state of the execution plan when you instantiate a golem-timeline job. Here you can see the worker information from which you can access the final result, as well as the leaf worker to which you will need to send the events to. Golem provides interfaces (out of scope for this blog) to get these results.
- Kick off event feeder — a simple Pulsar consumer sending the events to event processors
- The job keeps running. The event processors continuously stream.
- Invoke get_timeline_result in result_worker, returning the timeline value
- Every worker has the same function that can be called at anytime, implying there is a consistent way to get the current status of every worker.
We benefit the following from using Golem Timeline:
True Application Level Observability
At the core, the declarative DSL allows us to inspect what’s going on, and with golem we also know which worker is taking care of which part of the computation too — forever! It is not a random bar diagram of a plethora of tasks and executors with it’s progress.
Absolute clarity on Delayed Events
Say Worker1is handling TLEventToState, and Worker2is handling Not(TLEventToState(..)) .
Let’s say we have a Worker3handling TLEventToState for some other event.
let t1 = TLEventToState(col('playerStateChange')) == 'buffer';
let t2 = !t1
let t3 = TLEventToState(col('cdnChange')) == 'CDN1';
let result = And(t2, t3)
result.at(2pm)At 2 PM, if the result returns None, it suggests that some events related to CDN may not have reached its worker. You can verify this assumption by checking if the worker is specifically handling CDN events durably. In Golem Timeline, delayed events are inherently managed without extra cost. If a worker needs to wait for an event for a month or a year, it can do so. Alternatively, you can check the result_worker again later to see if it produces a different result.
Simple Internal Durable State
Golem Timeline Framework is Simple
- At the core every worker should have a complete knowledge of what every other worker
- All of this metadata, as well as data is just in-memory states. Why? Golem takes care of the rest.
- Golem-timeline currently use only in-memory for anything it needs to persist!
- This means, golem-timeline framework itself is simple and contributors can onboard quickly.
Simply leading to In-Memory as the primary data source=
- Persistence during computation to attack failures doesn’t exist. Everything is in-memory as much as they can
- On demand computation mostly just rely on the information with in-memory by default
- It’s durability and reliability are all handled by Golem
Computation Reuse
In real-world scenarios, computation of a complex query involve running queries for primitives. For example, here is an example from the video distribution domain, where CompletionRate is derived from the primitives Total Number of PlayBack Attempts Count and Total Number of Completed Playbacks
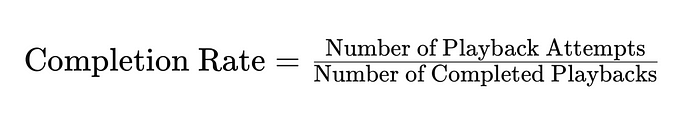
Once you start running a golem-timeline job to compute the above metrics, each worker will be responsible for computing certain parts of this computation. Note that, Golem-Timeline naturally may tackle this problem more like a map reduce job (it depends on the logic you write using DSL), where we will have some final reducer workers that pulls results from other intermediate workers and aggregate the results.
Let’s say as part of the above the computation, there is a reducer worker (rw1) that aggregates partial sums of playback attempts, and another (rw2) for completed playbacks, and a third (rw3) that divides these values.
The key point here is that when you run a completely separate job (by writing the DSL and deploying to the platform), which only calculates “total_playback_attempts_count”, your timeline infrastructure doesn’t need to start a new job to form the results. Why? Because the platform already knows that rw1 worker already has this result and timeline framework skips this job and simply pipe out the data from rw1. Alternatively user can directly hit rw1 (golem has interfaces to connect to worker, and it can be as simple as an http endpoint) and get the results..
Stream First Approach
In the previous example, some of you might be wondering:
Oh but my completion_rate job is finished already, so how can the next playback_attempts job reuse the result from a worker which was part of completion_rate job?
The answer to this question is where I am pointing out the fact we can reduce the blurness of stream vs batch in solving a big data problem. The answer to the above question is “completion_rate” job is running forever! Why ? Because, it is streaming events forever, and continuously updating the playback_attempts forever and forever in rw1 worker — and you can (or timeline framework itself) can poke this rw1 worker and ask “just tell me the current status of playback_attempts count”.
The r-w1 worker, part of the completion_rate job, continuously updates its in-memory data structure of total playback attempts indefinitely, ensuring uninterrupted operation thanks to Golem deployment. Consequently, any subsequent jobs can automatically reuse this worker if they also involve computing playback attempt counts. It operates without needing to access other data stores; the previous computation effectively acts as a data store for the next job. The beauty of this setup is that users of Golem Timeline don’t need to manually handle these complexities — they simply write the logic and deploy it.
Importantly, the results from r-w1 are not only accessible within the internals of the Timeline framework but also via an HTTP endpoint that developers can access to view these subcomputation results. This accessibility represents a significant advantage! The platform overhead is greatly reduced because any separate jobs developers spin up, especially for debugging purposes, do not require additional physical resources.
Handle Unordered Events For Free
We can’t expect the events to come in order to these workers. However, when plotting a timeline it’s easier to update the plot handled by a specific worker in golem timeline, as it simply uses Rust data structures in-memory to update these plots. It doesn’t need to update any underlying data store or any distributed queues.
Any derived plots are on-demand computation (i.e, continuous computations over the events happens only in the leaf node in golem-timeline), so refreshing your UI (or any digester/report mechanism) will reflect the entrance of an unordered event!
Simply put, needn’t handle unordered events in your DSL, because framework knows about it.
Compliance concerns
Firstly, any data that the business is concerned about can be stored in a persistent store. GolemTimeline is not stopping you from doing it.
Most probably this data is the final outcome of an entire job and not any intermediate data that exists while the job is running.
Overhead of employing Golem-Timeline in your platform
Using golem-timeline doesn’t necessitate a complete overhaul of existing company platforms. Many companies heavily rely on Kafka/Pulsar/Kinesis to stream events into their platforms. With Golem Timeline, you’re not altering this data flow. Deploying a Golem Timeline Job simply means it’s another job in your platform, akin to any other job if deployed on-premise. Over time, a suite of timeline jobs can gradually replace redundant tasks if necessary.
Should the user learn Rust to use the timeline DSL?
As of now, yes, users should learn Rust to use the timeline DSL. However, all that’s required is a basic understanding of Rust syntax. In the future, we plan to provide APIs in other languages of your choice.
Current Progress of Golem Timeline
Golem Timeline has sparked excitement within the Golem team itself. Soon, this repository will join the Golem organization, welcoming smart developers both within and outside the team to contribute to this open-source project.
We’re emulating use cases learned from consulting with companies to ensure Golem Timeline achieves production-grade quality. Specifically, our current focus is on coming up with an ergonomic abstraction for sharding data in a timeline worker cluster. This effort demands careful research and consideration, and we’re taking the necessary time to ensure its success. Stay tuned for updates on this front.
For those eager to learn more, you can watch my talk at LambdaConf, Colorado: Watch here.

